







Réseaux de neurones et apprentissage profond : les concepts
Publié en ligne le 24 août 2020 - Intelligence Artificielle -
L’intelligence artificielle (IA) est une discipline qui a fréquemment recours à des termes évocateurs et anthropomorphiques pour les concepts qu’elle manipule, mais son objet reste difficile à définir simplement. Sa dénomination elle-même, en utilisant le mot « intelligence », a focalisé une partie des controverses sur la comparaison avec les capacités humaines et, au-delà, sur la place même de l’Homme face à la machine. Pourtant, une bonne partie des questions soulevées (responsabilité juridique, explication des comportements, éthique dans les utilisations) se posent déjà à propos de nombreux systèmes informatiques fondés sur des algorithmes qui, pourtant, ne comportent aucun composant relevant des techniques de l’IA (en témoignent les controverses suscitées par le logiciel ParcoursSup pour décider de l’affectation des nouveaux bacheliers, celles liées à l’usage de machines de vote électroniques [1] ou encore, les controverses lors d’accidents d’avion pour déterminer la part de responsabilité de l’Homme et des automatismes).
Les techniques d’apprentissages à la base du renouveau actuel de la discipline ne sont pas en reste, avec en particulier le terme de « réseaux de neurones » renvoyant directement à l’image du cerveau humain. Pourtant, les neurones artificiels dont il est question n’ont qu’une analogie bien lointaine avec les cellules du cerveau humain (même si ces dernières ont servi d’inspiration aux modèles mathématiques utilisés). Et l’organisation même de notre cerveau est d’une complexité bien supérieure à celle des réseaux de neurones modélisés dans les ordinateurs ; il est donc sans valeur de comparer les deux à l’aune du nombre de « neurones ».
Les réseaux de neurones artificiels
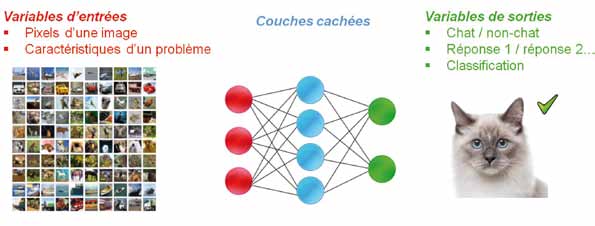
Le composant de base des réseaux de neurones utilisés en IA peut être schématisé comme une entité disposant de plusieurs entrées pouvant prendre des valeurs discrètes (par exemple binaires : 0 ou 1) et d’une sortie, elle aussi discrète. Une fonction mathématique va déterminer la sortie en fonction des valeurs d’entrée. Le « poids synaptique » (encore un terme anthropomorphique) associé à chacune des entrées permet d’en pondérer l’importance. Ces entrées pondérées sont ensuite additionnées pour déterminer la valeur de sortie.
Un réseau de neurones artificiel est une association d’un certain nombre de ces « neurones formels ». Le réseau est généralement organisé en couches successives où les sorties d’une couche constituent les entrées d’une autre. Les entrées du premier niveau modélisent le problème que l’on veut résoudre (par exemple, en associant chaque pixel d’une image dont on veut reconnaître le contenu à une entrée) et les sorties du dernier niveau représentent la réponse attendue (par exemple 1 pour dire que le système a reconnu un chat et 0 pour dire qu’il n’en a pas reconnu). Entre les deux, les valeurs calculées sont transmises d’une couche à la suivante.
Les couches intermédiaires construisent ainsi une fonction mathématique qui doit représenter le système de reconnaissance. La fonction mathématique implémentée par ces couches successives doit résoudre le problème posé (par exemple, reconnaître la présence d’un chat sur une photo codée par ses pixels). Toute la difficulté consiste à trouver les bons paramètres (poids synaptique et autres paramètres) de chacun des neurones afin d’obtenir les sorties désirées avec un minimum d’erreurs. C’est ce qu’on appelle la phase d’apprentissage. Un opérateur humain voulant régler manuellement chacun de ces paramètres (il y en a plusieurs milliers) n’aurait aucune chance de réussir cette tâche, car nulle part dans le système n’est codé explicitement ce qui caractérise un chat (moustaches, oreilles pointues, etc.). Il est donc impossible de raisonner directement sur les paramètres du réseau (ni, d’ailleurs, a posteriori, d’utiliser ces éléments pour expliquer la décision). Ce sont des algorithmes d’optimisation fondés sur des mathématiques sophistiquées qui permettent de faire varier progressivement les paramètres du réseau afin d’approcher le plus possible du résultat voulu (par exemple, la méthode dite d’apprentissage supervisée consiste à observer les erreurs de diagnostics sur des jeux d’essais labellisés, c’est-à-dire des images où l’on aura préalablement indiqué celles comportant un chat et celles n’en comportant aucun, et à remonter cette information dans le réglage du réseau).
« Deep learning » et « big data »
Cette approche est appelée « connexionniste » car elle est fondée sur le paramétrage d’un réseau connecté. Elle date de la fin des années 1950 dans son principe [2] mais a connu une véritable envolée dans les années 2000 grâce notamment aux capacités de calcul atteintes par les ordinateurs et à la mise à disposition d’un très grand volume de données (big data). Les réseaux de neurones ont alors pu embarquer des couches intermédiaires (« couches cachées ») en très grand nombre (jusqu’à une vingtaine, d’où le terme de deep learning, ou apprentissage profond). En lien avec la mise au point d’algorithmes d’apprentissage plus performants, des résultats vraiment impressionnants ont été obtenus dans de nombreux domaines.
Ainsi, par exemple, la reconnaissance d’images par apprentissage profond permet non seulement de reconnaître (avec cependant des erreurs) des visages au sein d’une foule en mouvement [3], mais aussi d’identifier des objets présents ou de lire des émotions sur les visages (peur, joie, mépris, tristesse, dégoût, surprise…) [4].

Des systèmes savent lire sur les lèvres d’une personne de façon bien plus efficace que le font les êtres humains [5]. D’autres se révèlent meilleurs que les êtres humains pour l’interprétation de clichés d’imagerie médicale [6]. Des systèmes sont capables de coloriser des images en noir en blanc avec des couleurs extrêmement réalistes [7], de composer de la musique en s’inspirant d’un style donné [8], de peindre des tableaux à partir d’un simple croquis [9]… La traduction automatique (par exemple, celle mise en œuvre sur la plupart des moteurs de recherche) s’appuie sur ces techniques d’apprentissage profond. Des intelligences artificielles arrivent à rédiger des articles de journaux sur la base de dépêches d’agence [10]. Dans les entreprises, partout où de grandes quantité de données sont disponibles, des applications voient le jour dans le domaine de la conception ou du diagnostic, par exemple. Sans oublier, bien entendu, les intelligences artificielles qui battent les champions du monde de certains jeux réputés complexes (jeu de go, jeu d’échecs).
Les risques d’un apprentissage biaisé
Pour autant, le « deep learning » reste tributaire de son apprentissage, et donc des données sur lesquelles il a pu s’entraîner. Celles-ci peuvent être partielles, biaisées, voir mal étiquetées, avec des conséquences parfois très préjudiciables.
En 2015, la société Amazon a dû écarter son « robot recruteur » qui favorisait systématiquement les candidatures masculines pour les postes techniques. Ce biais était dû au fait que l’intelligence artificielle avait été entraînée sur la base de données de profils des personnes déjà en place à des postes similaires au sein de l’entreprise, en grande majorité des hommes. Après avoir essayé de corriger ce problème, Amazon a finalement abandonné le projet, faute de pouvoir s’assurer que la sélection des candidats ne comporterait pas d’autres biais [11].

En 2016, c’est Microsoft qui a dû arrêter son expérience d’un robot conversationnel. Tay, de son nom, se présentait comme une adolescente fan de musique et de Pokémon et adoptant la manière de parler de cet âge-là. Elle était supposée apprendre et enrichir ses interactions au travers d’échanges avec des internautes. Elle était en particulier capable de dialoguer via son compte Twitter. Mais après seulement quelques heures, Tay commença à twitter de nombreux messages injurieux ou offensants, obligeant rapidement Microsoft à interrompre son expérience. L’analyse a posteriori a montré qu’un groupe d’utilisateurs du réseau social avait appelé à inonder le compte de Tay de messages à caractère raciste, antisémite ou misogyne. Tay n’a finalement fait que s’adapter à sa « base d’apprentissage » et a reproduit le comportement qu’elle observait [12].
Les IA derrière les logiciels de reconnaissance faciale sont aussi sur la sellette. Ces systèmes sont très performants et s’avèrent capables de reconnaître sur des vidéos, quasiment en temps réel, les visages des personnes composant une foule ou d’un groupe de personnes. En 2019, la Chine a rendu obligatoire la reconnaissance faciale pour tout achat d’une carte SIM (l’obtention d’une ligne téléphonique nécessite le passage devant une caméra qui enregistre les données qui seront utilisées par la reconnaissance faciale). Aux États-Unis, en 2016, la moitié des adultes seraient déjà enregistrés dans des bases de données dédiées [13]. Pourtant, la reconnaissance faciale est loin d’être complètement au point. Les erreurs d’identification sont encore nombreuses. En particulier, aux ÉtatsUnis, comme l’apprentissage s’est fait principalement sur des personnes de couleur blanche, les erreurs sont bien plus fréquentes quand il s’agit de reconnaître des individus afro-américains ou d’origine asiatique, avec les risques associés quand on utilise ces programmes pour identifier dans une foule des délinquants présumés, par exemple en analysant les vidéos des personnes débarquant d’un avion dans un aéroport [14].
Ces remarques n’enlèvent rien à la puissance sans cesse croissante des algorithmes d’apprentissage, mais elles illustrent quelques limites actuelles, dont certaines sont dues à des problèmes scientifiques de fond qui sont loin d’être résolus. En particulier, ces algorithmes sont très dépendants de la qualité des données utilisées lors de la phase d’apprentissage ainsi que de la qualité de l’étiquetage associé.
1 | Enguehard C, Le vote électronique est-il transparent, sûr, fiable ?, SPS n° 320, avril 2017. Sur afis.org
2 | Rosenblatt F, “The perceptron : a probabilistic model for information storage and organization in the brain”, Psychological Review, 1958, 65 :386-408.
3 | Biget S, « Reconnaissance faciale : 1 seconde pour repérer un visage parmi 36 millions », Futura Science, 11 mai 2012.
4 | Noroozi F et al.,“Survey on Emotional Body Gesture Recognition”, IEEE Transactions on Affective Computing, 16 octobre 2018.
5 | Zaffagni M, « L’IA de Google DeepMind lit sur les lèvres mieux qu’un humain », Futura Science, 25 novembre 2016.
6 | Haenssle HA et al., “Reader study level-I and level-II Groups, Man against machine : diagnostic performance of a deep learning convolutional neural network for dermoscopic melanoma recognition in comparison to 58 dermatologists”, Ann Oncol, 2018, 29 :1836-42.
7 | Auclert F, « Cette app met en couleurs vos vieilles photos en noir et blanc », Futura Science, 9 avril 2019.
8 | Zema A, « Une intelligence artificielle compose une œuvre musicale à partir d’une partition inachevée de Dvořák », Le Figaro Tech & Web, 18 juin 2019.
9 | Boudet A, « Vincent, l’IA qui transforme les croquis en œuvres de Van Gogh ou de Picasso », Numerama, 1er octobre 2017.
10 | Lesage N, « Robot journaliste : en un an, une IA créée par le Washington Post a publié 850 articles », Numerama, 15 septembre 2017.
11 | “Amazon ditched AI recruiting tool that favored men for technical jobs”,The Guardian, 11 octobre 2018.
12 | “In 2016, Microsoft’s Racist Chatbot Revealed the Dangers of Online Conversation”, IEEE Spectrum, 25 novembre 2019.
13 | “Half of US adults are recorded in police facial recognition databases, study says-, The Guardian, 18 octobre 2016.
14 | “Many Facial-Recognition Systems Are Biased, Says U.S. Study”, The New York Times, 19 décembre 2019.
Publié dans le n° 332 de la revue

Partager cet article




L'auteur
Jean-Paul Krivine

Rédacteur en chef de la revue Science et pseudo-sciences (depuis 2001). Président de l’Afis en 2019 et 2020. (…)
Plus d'informationsIntelligence Artificielle
L’intelligence artificielle (IA) suscite curiosité, enthousiasme et inquiétude. Elle est présente dans d’innombrables applications, ses prouesses font régulièrement la une des journaux. Dans le même temps, des déclarations médiatisées mettent en garde contre des machines qui pourraient prendre le pouvoir et menacer la place de l’Homme ou, a minima, porter atteinte à certaines de nos libertés. Les performances impressionnantes observées aujourd’hui sont-elles annonciatrices de comportements qui vont vite nous échapper ?
Intelligence artificielle générale : entre fantasmes et réalité
Le 21 septembre 2025![[Blois - mercredi 17 juin 2026 – matinée] Intelligence artificielle et santé](local/cache-gd2/59/a77070eed7b688149a5eeb96e78de3.jpg?1779193266)
![[Conférence en ligne - Mercredi 3 juin 2026 à 20h00] Faut-il avoir peur de l'intelligence artificielle ?](local/cache-gd2/12/ff8e7e0febe7fdf834617693fd7383.png?1779909501)
![[Quimper - Jeudi 7 mai 2026] Faut-il craindre l'intelligence artificielle ?](local/cache-gd2/aa/44527a70f7a9581abc0ebe20d9c129.jpg?1768404452)

Intelligence artificielle : conscience, autonomie et risques existentiels
Le 20 novembre 2025










